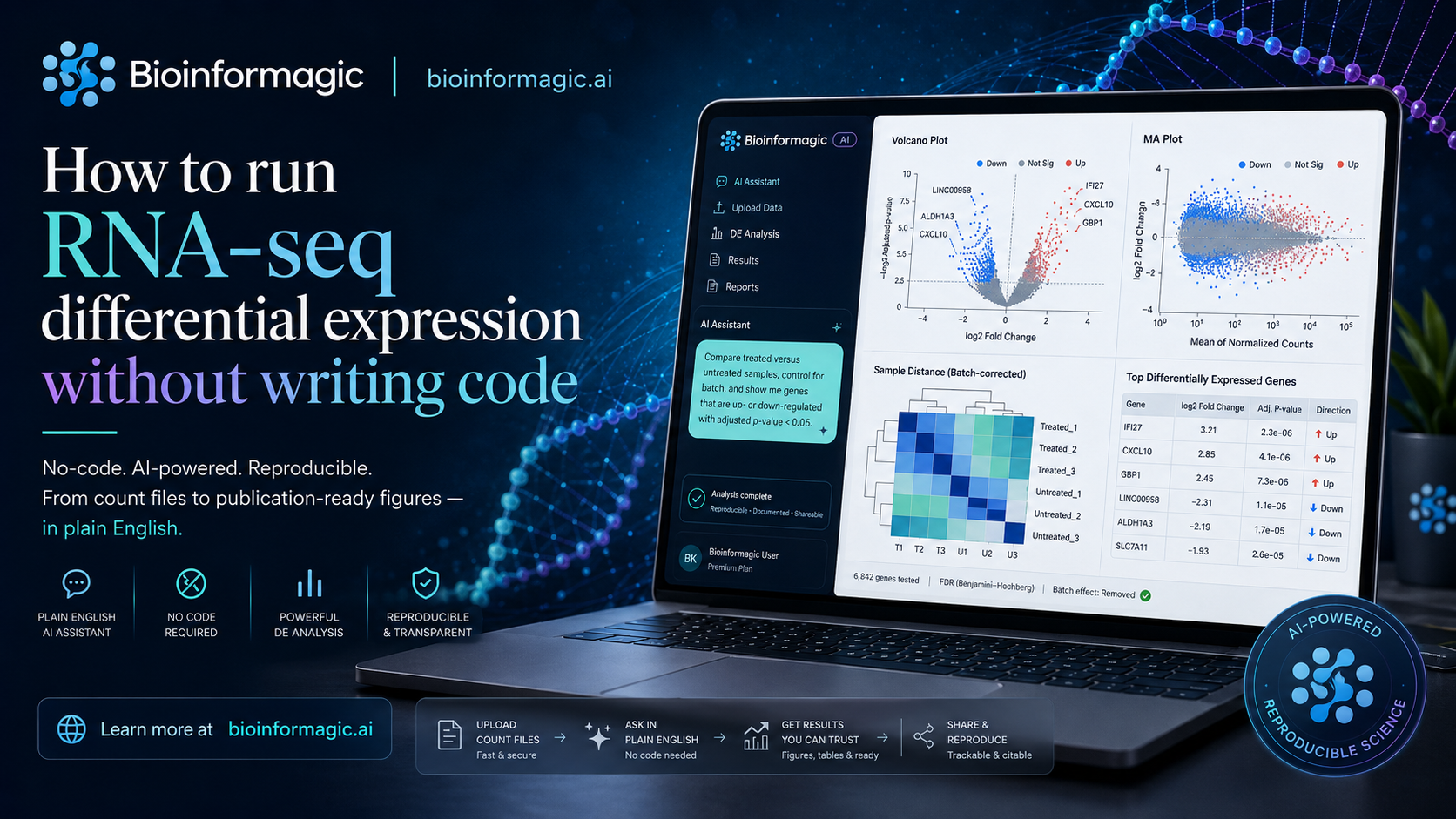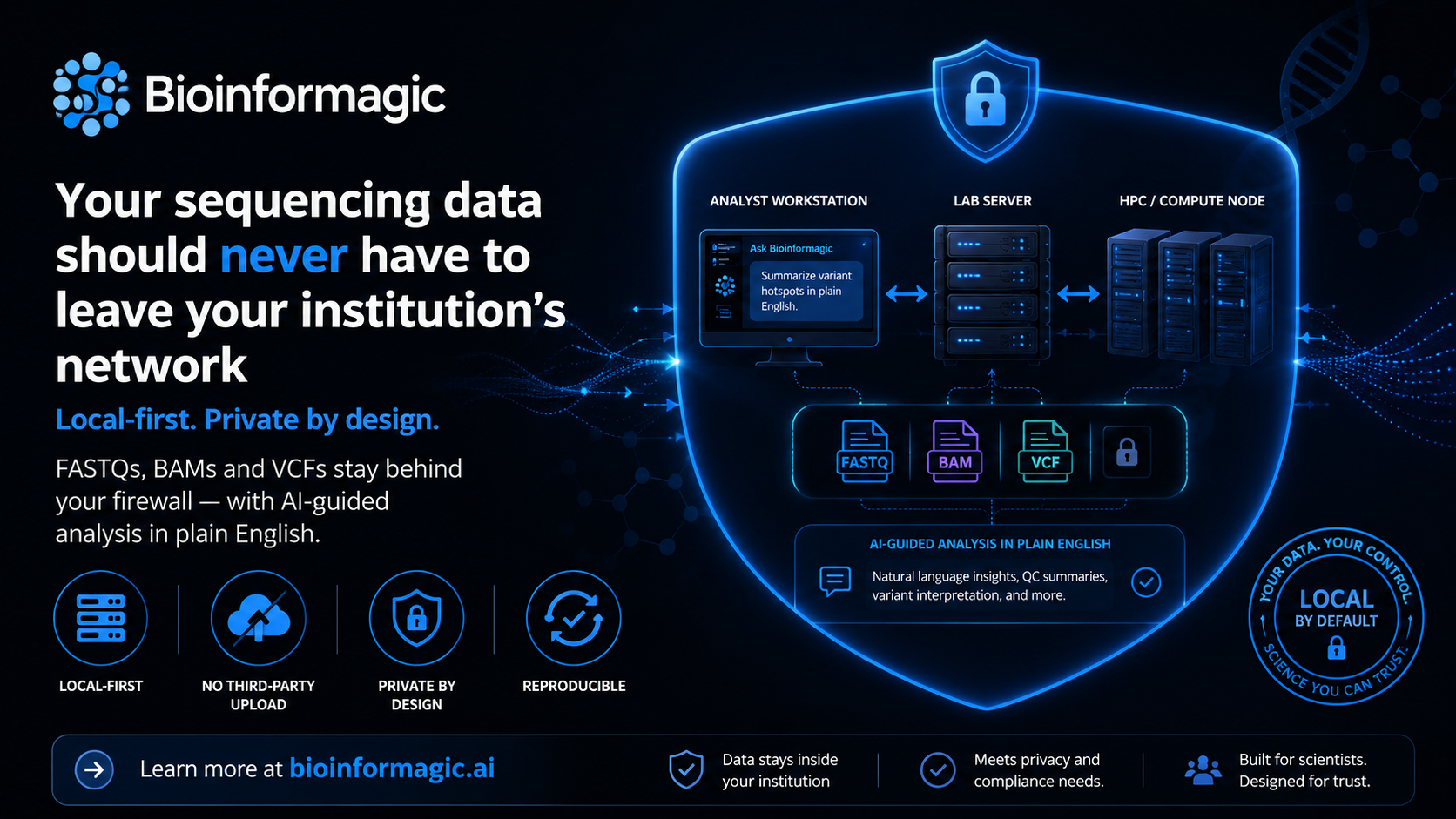
Here's a pattern you've probably hit. You find a slick web tool that promises to analyse your RNA-seq or variant data. You get to step one. Step one is "upload your FASTQ files."
For a lot of researchers, that's where the tool quietly stops being usable — because those files aren't really yours to upload. They live on your institution's storage, under your institution's rules.
Why "just upload it" is a bigger ask than it sounds
- Governance. Human sequencing data often sits under IRB approvals, data-use agreements, or GDPR/HIPAA obligations that simply don't allow it to land on a third party's servers.
- Size. A single whole-genome sample can be tens of gigabytes. Uploading a cohort over a campus connection is measured in days, not minutes.
- Cost. Cloud storage and egress fees are easy to start and hard to stop. The bill rarely shrinks on its own.
- Trust. Once data leaves your machine, "deleted" becomes a promise you can't verify.
A different default: the analysis comes to the data
Bioinformagic flips the usual arrangement. Instead of shipping your reads to someone else's server, the assistant orchestrates the pipeline inside your own institutional network — on the workstation, lab server or HPC node you already use. Your FASTQs, BAMs and VCFs stay exactly where they are. The AI plans the workflow, but the heavy lifting — alignment, quantification, variant calling — runs against files that never cross your network boundary.
The most private architecture is the one where the sensitive data never travels in the first place.
What actually leaves your network
To plan a workflow, the assistant needs to understand your intent and the shape of your data — not its contents. It works from metadata like file types and your plain-English description. Your raw reads and results stay behind your institution's firewall and are never part of that conversation.
The quiet benefits of local-first
- No upload wait. Analysis starts when you do, not after a multi-hour transfer.
- Predictable cost. You use compute you already have, instead of metered cloud instances.
- Easier approvals. "Nothing leaves the building" is a much shorter conversation with a data-governance office.
- Real reproducibility. The environment that ran your analysis lives next to the data that produced it.
Local doesn't mean limited
A fair worry: does staying local mean giving up the convenience that made cloud tools attractive? It shouldn't. You still get a guided, plain-English experience and publication-ready outputs. The difference is purely where the computation happens — and who can see your data while it does. (Spoiler: just you.)
Built for sensitive science
If your data has ever been the reason you couldn't use a tool, that constraint shaped how we built this one. Join the waitlist and tell us about your privacy requirements — they're a feature we want to design around, not an edge case.