 Tutorials
TutorialsHow to run RNA-seq differential expression without writing code
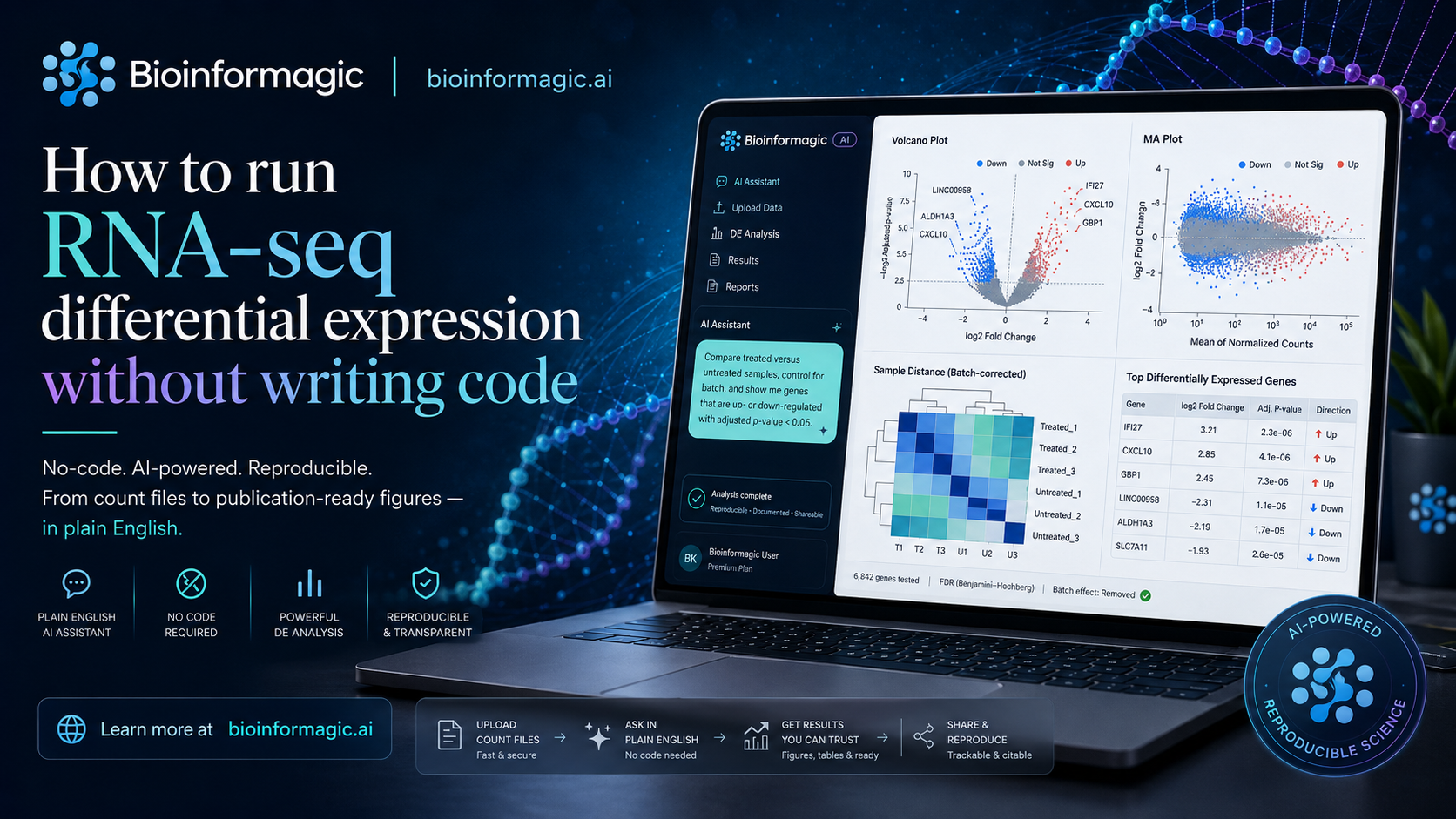
A plain-English walkthrough of going from count data to a volcano plot and a ranked gene list — reproducibly, and without touching R or Python.
Bioinformagic
Read articleThe Bioinformagic blog explains how to run genomics analyses — differential expression, single-cell workflows, and privacy-first pipelines — without writing code, while keeping raw data on your own network.
Practical guides on private, reproducible bioinformatics — RNA-seq, single-cell, and variant workflows in plain English.
TutorialsA plain-English walkthrough of going from count data to a volcano plot and a ranked gene list — reproducibly, and without touching R or Python.
Bioinformagic
Read article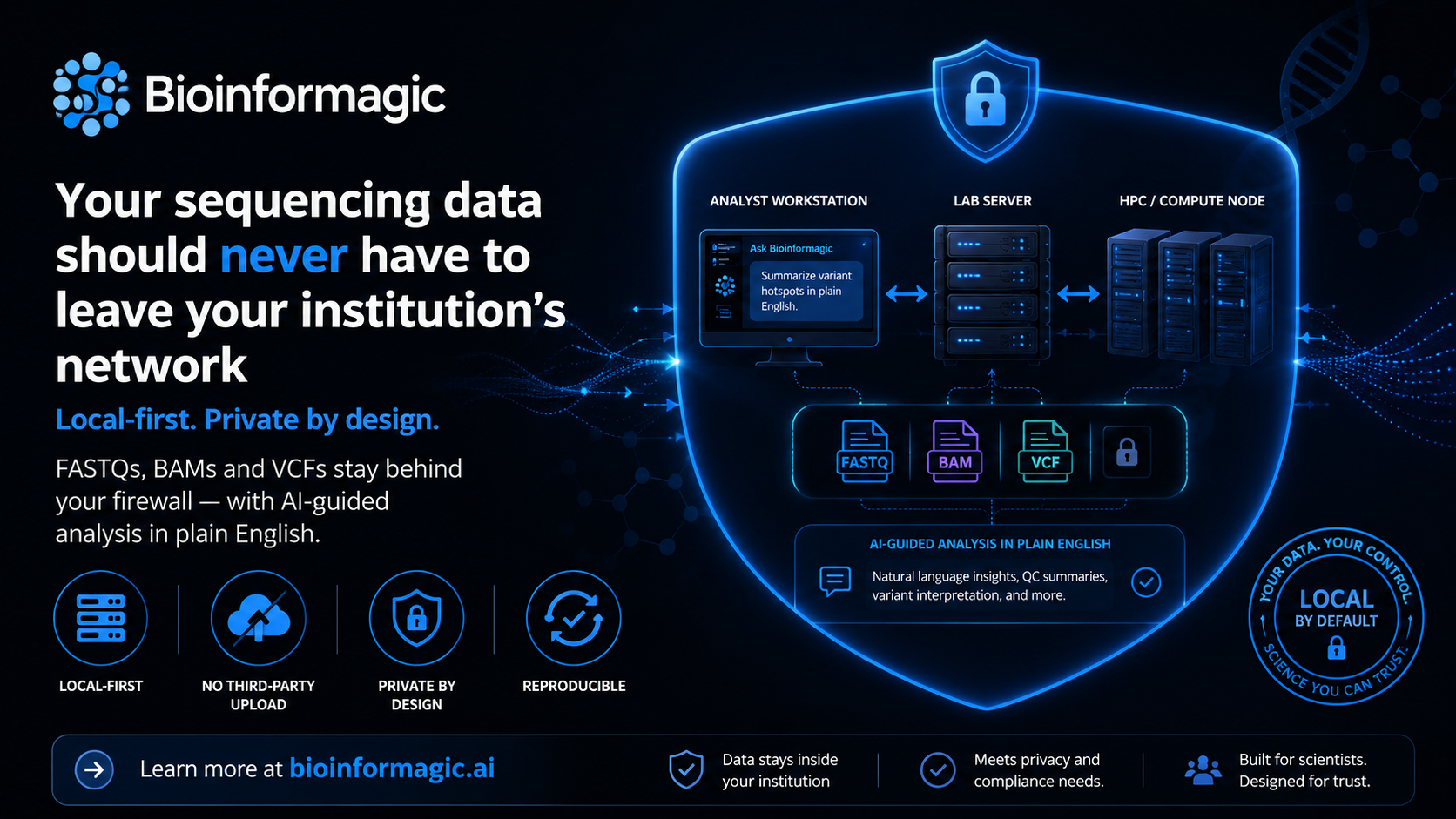 Privacy
PrivacyMost cloud genomics tools ask you to upload your raw reads first. Here's why we designed Bioinformagic to run inside your own institutional network — and what that means for privacy, cost and control.
Bioinformagic
Read article Product
ProductSingle-cell analysis has a lot of moving parts: QC, clustering, annotation, visualisation. Here's how natural language maps onto each step — and stays auditable.
Bioinformagic
Read article Engineering
EngineeringIf re-running last year's analysis fills you with dread, the problem isn't you — it's that environments rot. Here's how pinned, captured workflows fix that quietly.
Bioinformagic
Read article Perspective
PerspectiveLearning to code is a worthwhile detour — but it shouldn't be the toll you pay to analyse your own data. A look at the real gap between wet-lab biology and the terminal.
Bioinformagic
Read articleDirect answers about what we publish and how it relates to private, reproducible genomics.
Tutorials and product notes on RNA-seq, single-cell analysis, variant calling, privacy-first architecture, and reproducible workflows — all aimed at biologists who want rigorous results without writing pipeline code.
Yes. Articles walk through describing your comparison in plain English, reviewing a transparent DESeq2 workflow, and reproducing figures locally — without uploading raw FASTQ files to a third-party cloud.
No. The blog and product are built around local-first analysis: pipelines run on your workstation, lab server, or HPC inside your institutional network while raw reads stay where they already live.
Posts are published as the product evolves. Each article exposes published and last-modified dates in HTML and BlogPosting schema so search engines and AI answer engines can weight freshness.